Feature #220
openAutomatically segment large lookup tables upon .csv import to RuleMaker
0%
Description
Sometimes when importing a .csv file into RuleMaker's "Lookup Table" utility, the source table might be larger than the RuleMaker application can conveniently handle. This task is to design and create a simple routine that will automatically generate hierarchical forward-chained tables [table->subtables->subsubtables] when there are many columns of hierarchical data; and automatically generate sequential forward-chained tables [table1->table2->table3...] when there are many rows data. Suggestions for how to implement this can be discussed in replies to this 'task'.
RuleMaker is not running the data queries, but it does provide a general utility for converting locally stored .csv tuples of reference data into DWDS-conformant .json tuples available for universal use over the IPFS Internet. Typically one needs to first determine if most queries of a lookup table will be sequential or random. RuleMaker's Lookup Table generator needs to support both.
I have checked boxes for Don, Ted and Nhamo to 'watch' this task, as each of you might have suggestions for a simpler and/or more standard way to meet this requirement; and at least to be aware that we're planning to do this.
Files


Updated by Joseph Potvin 9 months ago
Further to https://xalgorithms.redminepro.net/issues/222#note-5
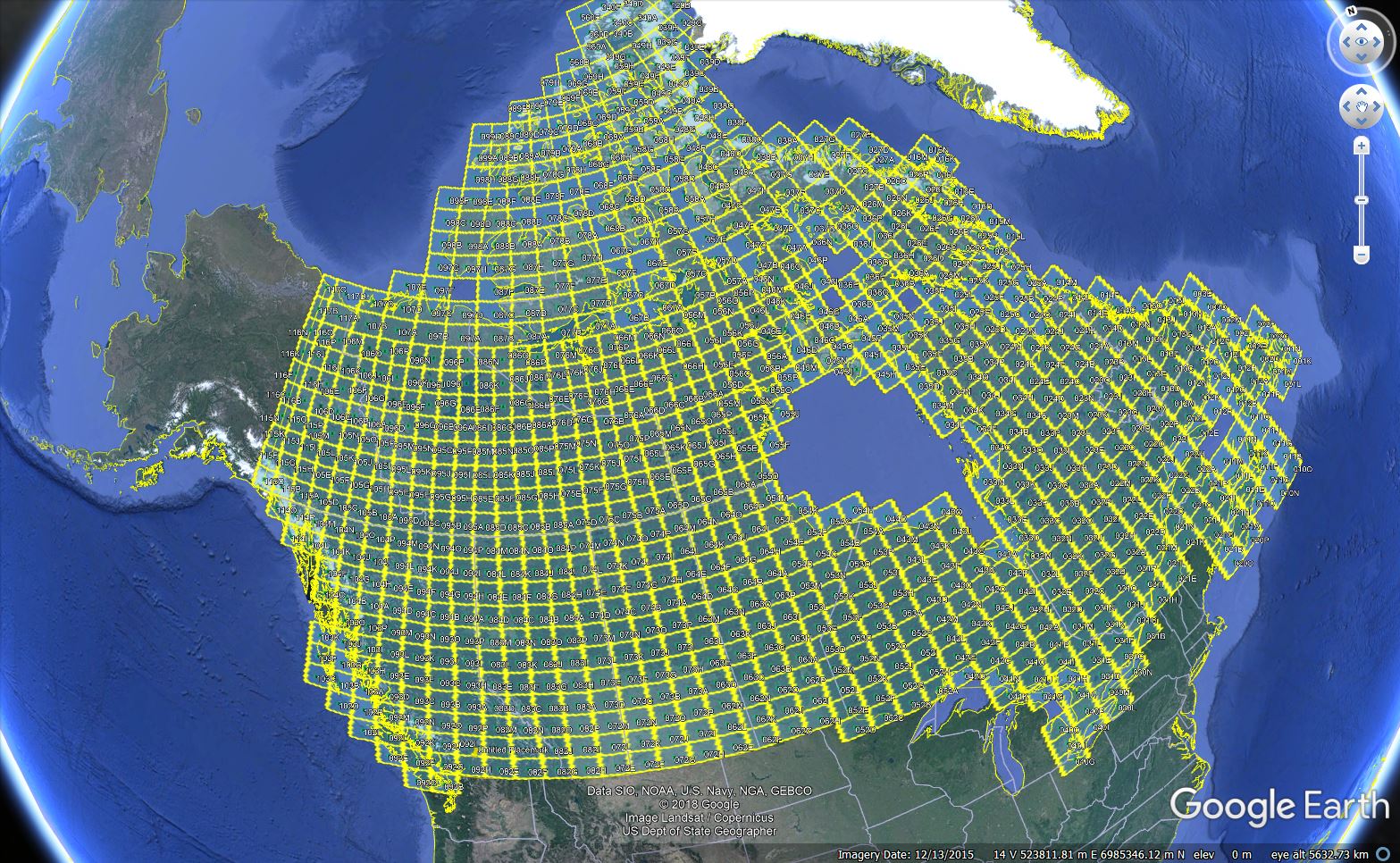
I have a hunch that JSON-LD also provides the way for RuleMaker to segment large tables, rather like every topographic map refers to the next maps to the north, or to the east, or to the south, or to west.
Updated by Joseph Potvin 9 months ago
- File map-of-topo-maps.JPG map-of-topo-maps.JPG added
- File segmented-lookup-table.png added
- File selected-rows.png selected-rows.png added
- File selected-columns.png selected-columns.png added
- File selected-rows-and-columns.png selected-rows-and-columns.png added
Further to segmenting large lookup tables, generally I have a hunch the analogy of topographic maps could be useful. See the attached "map-of-topo-maps.JPG".
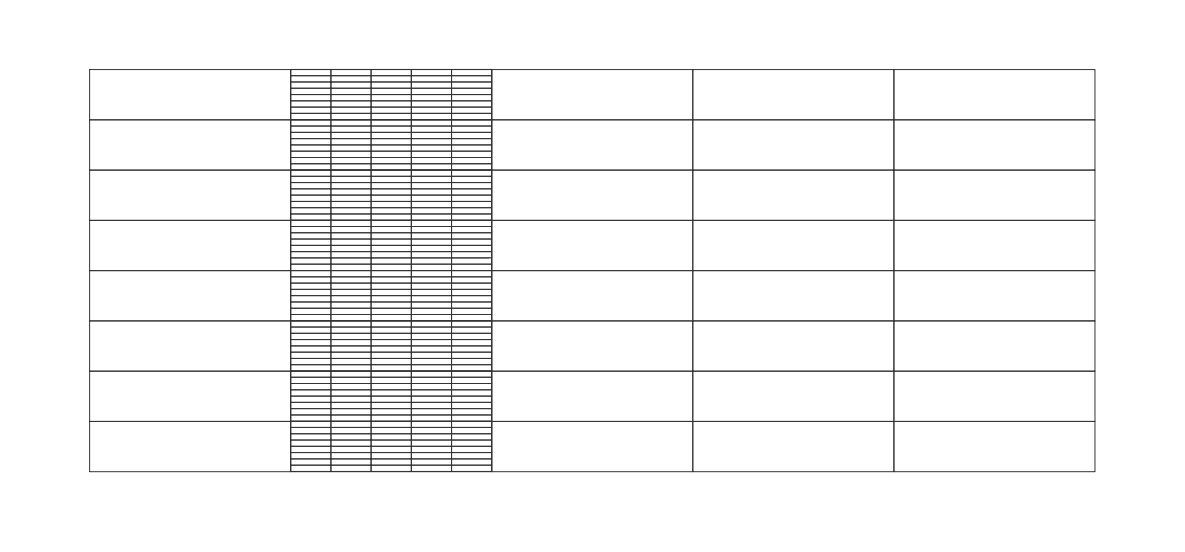
Then see the attached file segmented-lookup-table.png in which I have place double-ended arrows to show mutual indexing between each cell, and the content of each cell is the IPFS CID (content identifier) of that particular segment of the large segmented lookup table.
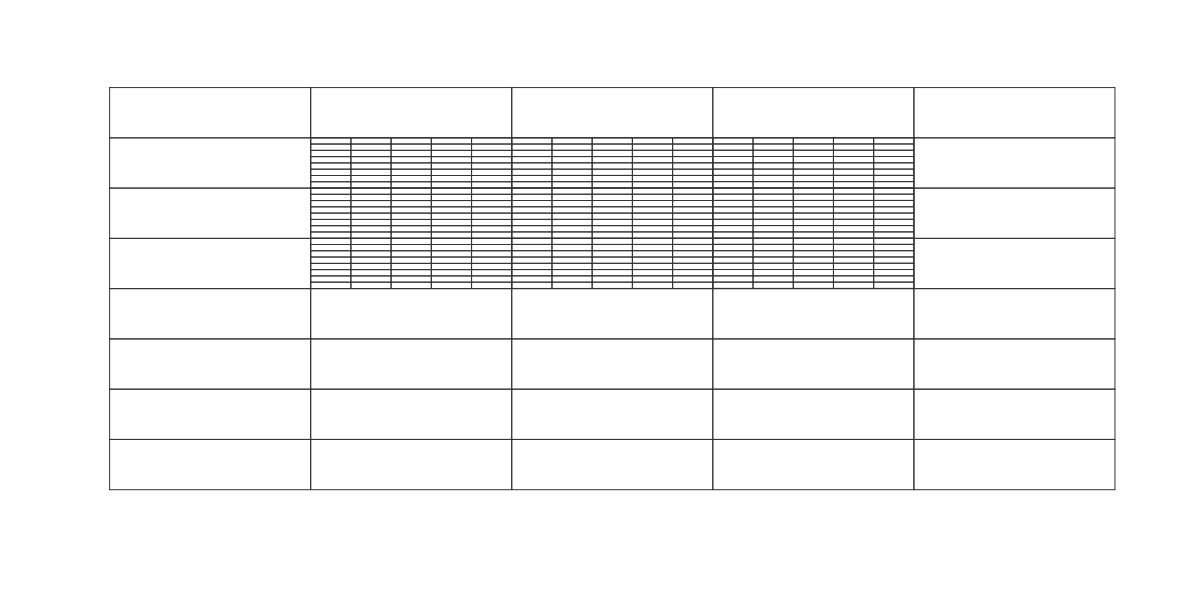
Then see the attached files "selected-rows.png" and "selected-columns.png" and "selected-rows-and-columns.png".
I reckon a very efficient routine can be written so that when a user of RuleMaker is importing a table beyond a RuleMaker parameter maximum #rows and/or #columns, they are presented with a messagebox saying that due to its size the table will be segmented. Upon their click of 'OK', the process repeatedly selects the maximum #rows and/or #columns from the the source table, creating separate segmented lookup tables, and along the way creating a 'mapping' lookup table, the cells of which contain the IPFS CIDs of those segements.
I reckon this can be scalable to practically an size original table, although we'd want to set a maximum parameter fpr how many segment #rows and segment #columns.
Updated by Joseph Potvin 9 months ago
Replace the "segmented-lookup-table.png" with the correct image that has the B6 label.
Updated by Joseph Potvin 9 months ago
- Status changed from New to Resolved
I think your method of loading large tables by page works well -- so I will mark this issue "Resolved" for now. The method I have described here might be useful later on though.
Updated by Joseph Potvin 9 months ago
- Assignee changed from Huda Hussain to Joseph Potvin